Introdução
Se voltarmos alguns bons anos, quando queríamos rodar uma aplicação em uma máquina com um sistema operacional, era necessário realizar uma série de configurações no ambiente, instalar diversos componentes, além de ajustar o hardware para suportar a carga de trabalho.
Pouco depois, surgiu a virtualização, que adicionou uma camada de abstração e isolamento entre o sistema operacional e hardware, o que chamamos de hipervisor. Ela possibilitou um melhor aproveitamento do hardware e a execução de vários sistemas isolados em diferentes máquinas virtuais. Porém, ainda precisávamos instalar e configurar o ambiente, suas dependências e fazer demais ajustes. A portabilidade era um caso à parte, o que tornou muito comum a frase: "Na minha máquina funciona!".
A containerização veio como uma forma mais leve e prática de empacotar as aplicações junto com tudo aquilo que elas necessitam para rodar: bibliotecas, dependências e demais configurações. Isso facilitou não só a execução, mas também o versionamento e portabilidade das aplicações.
E se podemos falar de uma plataforma que "democratizou" a containerização, essa é o Docker. O querido esteve e ainda está presente desde o desenvolvimento local até pipelines de CI/CD e ambientes de produção - e iremos falar melhor sobre isso no decorrer deste artigo.
Então, para alinharmos: o objetivo aqui é trazer um overview sobre o Docker, focando apenas no básico para que você possa progredir no mundo dos containers, caso assim deseje.
Bora lá?
O que é o Docker e o que são containers
O Docker é uma plataforma open source que viabiliza o desenvolvimento, distribuição e execução de aplicações. Criado em 2013 e baseado no LXC (Linux
Containers), pela até então chamada dotCloud, o Docker buscava resolver uma das grandes dores de cabeça no desenvolvimento de aplicações.... Sim, o famoso: "na minha máquina funciona".
Isso acontece porque o Docker utiliza o conceito de containers, que garantem que os aplicativos e suas dependências sejam "empacotados". Ou seja, que eles possam funcionar de forma consistente em qualquer ambiente.
Falando sobre os famigerados containers, a palavra-chave aqui é: isolamento. Isto porque eles são uma forma de agrupar uma aplicação e suas dependências, utilizando o kernel do sistema operacional do host, ou seja, da máquina (virtual ou física) onde está rodando. Assim, eles possibilitam o isolamento lógico (de processos, rede, usuários, etc.) e o isolamento de recursos (CPU, RAM, I/O), garantindo que a aplicação funcione de forma consistente e segura.
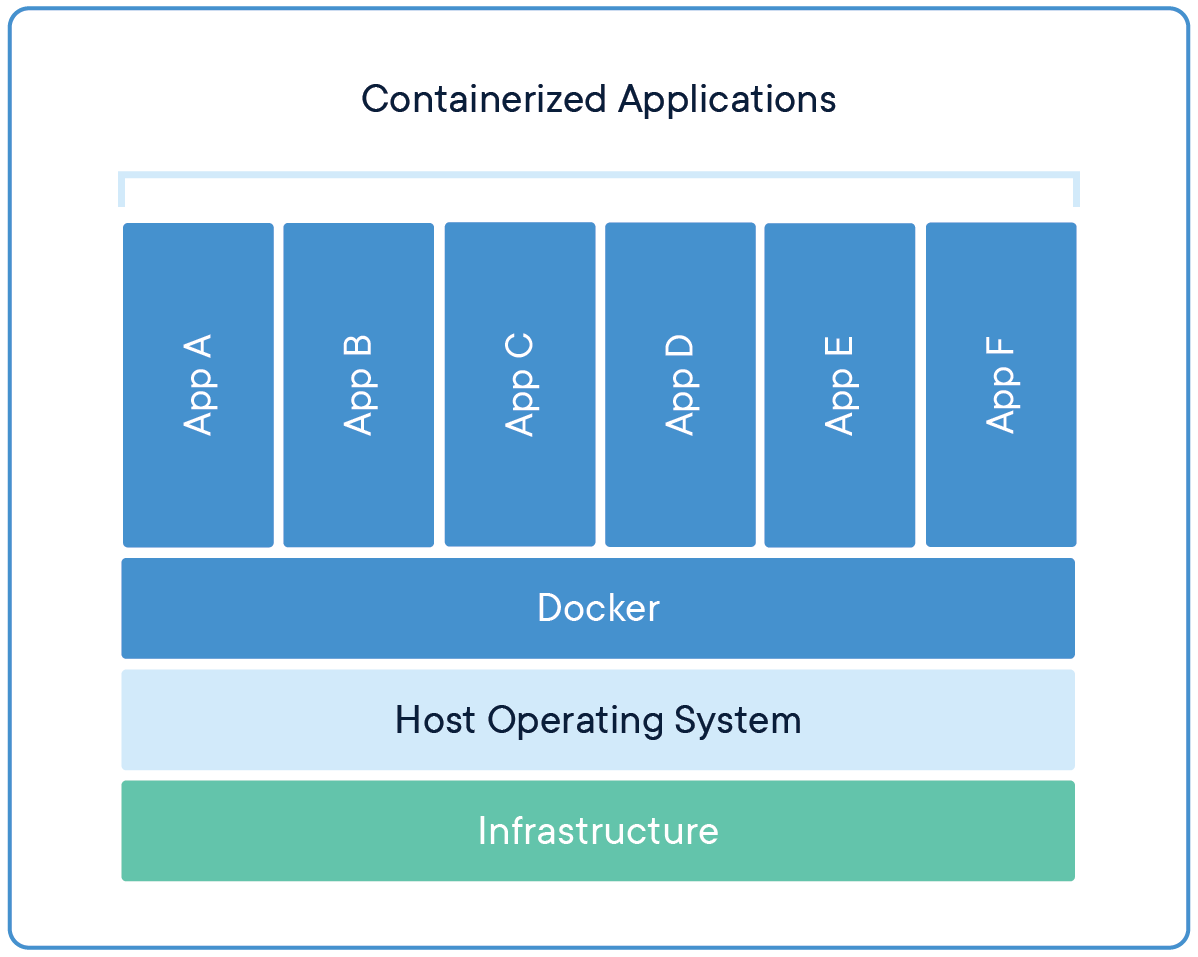
From: docker.com
Toda essa mágica ocorre por causa de funcionalidades do kernel Linux, especificamente dos:
- cgroups (Grupos de controle), que permitem o isolamento de recursos como CPU, memória, etc.;
- e os Namespaces, que são responsáveis por fazer com que cada container possua seu próprio environment, ou seja, cada container terá a sua árvore de processos, pontos de montagens, isolamento de filesystem, network, usuários, e por ai vai.
Ah, e não podemos esquecer do Chroot, uma syscall do Linux que permite alterar o diretório raiz de um processo e seus filhos.
Embora o Docker seja a solução mais popular, ele não foi a primeira nem é a única forma de executar containers. Mas, sem dúvidas, foi a solução que mais se destacou e se consolidou como ferramenta de conteinerização.
Quando usar o Docker?
Há quem diga que "o Docker já era" ou que ele não faz mais sentido hoje em dia. Na verdade, temos um ponto a ser discutido aí: não é que o Docker tenha caído em desuso, mas sim que, quando começamos a trabalhar com muitos containers e a dividir as aplicações em diversos serviços menores (o que chamamos de arquitetura de microsserviços), o gerenciamento do ambiente pode se tornar extremamente caótico.
Em um ambiente de produção, apenas dividir tudo em microsserviços e rodar containers não é o bastante. Precisamos escalar de forma rápida, garantir a alta disponibilidade, monitorar recursos, entre outras tarefas. Fazer isso com 10 containers é moleza, mas imagine fazer o mesmo centenas ou milhares deles?
Para lidar com toda essa complexidade, existem as ferramentas de orquestração de containers, como o Kubernetes. Os orquestradores automatizam o ciclo de vida dos containers, cuidando de tarefas que seriam impossíveis de fazer "na mão" em larga escala.
Portanto, usar o Docker sozinho em cenários de produção não é mesmo o ideal. Porém, ele continua sendo uma excelente ferramenta a ser usada nos seus estudos, no processo de compreender o desenvolvimento e de realizar testes locais. Ele é a porta de entrada para o mundo dos containers.
Além disso, ele ainda está como pano de fundo por trás da mágica dos orquestradores, já que utilizam container runtimes (como o containerd, que veio do próprio Docker) para criar e executar os containers. No fim das contas, mesmo quando ele não aparece no palco principal, o padrão que o Docker criou é o que sustenta todo esse ecossistema.
💡
OBS: Não se engane! Sabemos que para grandes ambientes de produção o uso do Docker "puro" não é recomendável, maaaaas infelizmente ainda existem muitos negócios que o utilizam dessa forma. Então, pode ser que você se depare com um cenário sem um orquestrador e cheio de containers Docker para gerenciar.... Eu lhe desejo boa sorte! 👀
Agora que entendemos o que é e quando usar o Docker, vamos colocar a mão na massa!
Instalando o Docker
Por padrão, vamos considerar a instalação do Docker no Linux. Para o nosso exemplo, estou usando uma Vagrantbox com o Ubuntu Jammy 22.04 (LTS) e também meu Pop!_OS, mas você pode utilizar a distro que melhor lhe agradar ou que for mais acessível para o momento.
Para seguirmos, abra o terminal e rode o seguinte comando:
## Executar o script
curl -fsSL https://get.docker.com | bash
Não tem muito segredo aqui: estamos usando um script oficial para automatizar o processo de instalação do Docker Engine (daemon + CLI) e configurar os repositórios, pacotes e dependências.
A saída do script irá trazer a versão do Docker Engine instalado:
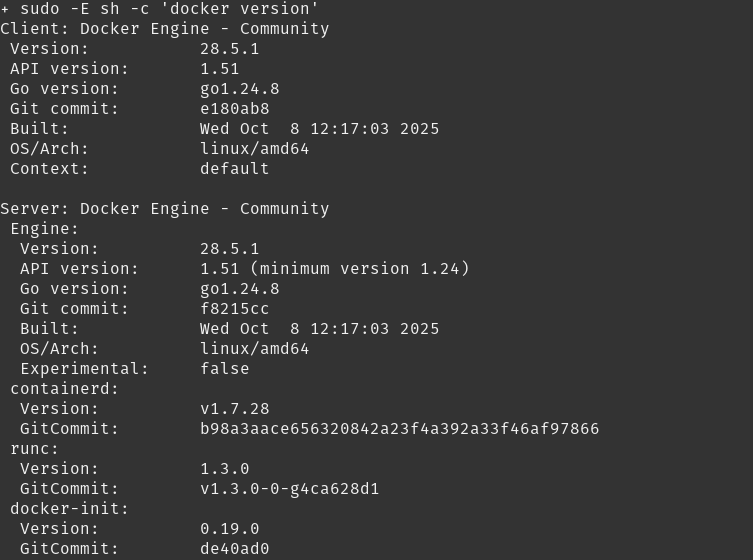
Agora, vamos facilitar a nossa vida e permitir executar os comandos do Docker sem a necessidade de usar o sudo toda hora, utilizando o modo rootless (outra forma comum seria adicionar o seu usuário ao grupo docker).
## Para rodar os comandos sem o sudo
dockerd-rootless-setuptool.sh install
########## BEGIN ##########
sudo sh -eux <<EOF
# Install newuidmap & newgidmap binaries
apt-get install -y uidmap
EOF
########## END ##########
Para testar se deu certo, você pode rodar os comandos:
## Ver a versão do Docker
docker version
## Rodar a imagem do hello-world
docker run hello-world
Perceba que, ao executar o docker run, o Docker vai baixar a imagem hello-world (pois não a temos localmente) e executar um container. Vamos falar sobre a execução de containers depois, mas a saída que você verá é mais ou menos esta:
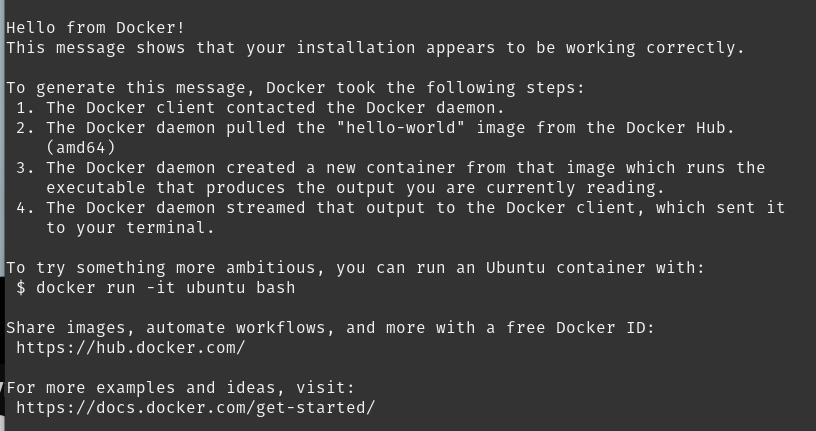
Show, né? Para instalar o Docker no Windows ou Mac, você pode utilizar o Docker Desktop.
O que são imagens e como criar um Dockerfile
No Docker, as imagens são como moldes: uma abstração da infraestrutura em estado de leitura (read-only), a partir de onde será criado o container. Uma vez gerada a imagem, ela é imutável e não "roda" sozinha. Em resumo, ela apenas fornece as instruções a partir das quais um container é criado.
Já os containers são instâncias "vivas" de uma imagem. Eles podem ser criados, iniciados, parados, movidos ou excluídos. Em geral, um container nasce isolado dos demais containers e da máquina host. E ele só pode ser criado a partir de, e somente de, uma única imagem.
Para criarmos nossa primeira imagem, vamos utilizar um arquivo chamado Dockerfile e inserir nele o conteúdo abaixo:
### Imagem base
FROM ubuntu:22.04
## Executar comandos durante a criação da imagem
RUN apt-get update && apt-get install nginx -y
## Expor uma porta
EXPOSE 80
## Executar comandos quando o container for executado
CMD ["nginx", "-g", "daemon off;"]
Agora, vamos entender com calma cada etapa desse Dockerfile:
FROM - aqui nós informamos qual imagem usaremos como base (no nosso caso, é a Ubuntu 22.04). É o ponto de partida sobre o qual vamos construir nossa solução;RUN - aqui nós informamos quais comandos serão executados no momento de criação (build) da imagem;EXPOSE - serve para expor uma porta (a-ha!). Com ele, definimos qual porta o container vai "ouvir";
- Aqui cabe uma ressalva: isso não abre a porta por si só, mas documenta e facilita quando rodarmos o container.
CMD - aqui informamos qual comando será executado por padrão quando o container iniciar a partir dessa imagem, ou seja, é o que vai rodar quando o container subir. Entendendo um pouquinho:
nginx - vai iniciar o Nginx server;-g e daemon off - serve para impedir que o Nginx gere seus processos e depois os encerre. Dessa forma, ele vai rodar em primeiro plano e evitar que o container morra.
Salve o arquivo e bora seguir para os próximos passos.
Buildando a imagem e rodando o container
Agora é a hora de fazer a mágica e transformar esse Dockerfile em algo real. Para isso, usamos o comando de build:
## Buildar
docker image build -t meu-nginx:1.0 .
Onde:
docker image build: é a instrução básica para criar uma imagem;-t meu-nginx:1.0: a flag -t se refere a tag, e serve para darmos um nome e uma versão para a imagem, que no caso vai ser meu-nginx:1.0. Caso não informemos a versão, o Docker vai colocar :latest como padrão;.: o ponto no final indica o contexto de build, e aqui estamos informando ao Docker que o Dockerfile está no diretório atual.
Já temos uma imagem pronta, porém, ela ainda não está rodando. Precisamos executar a nossa imagem, ou seja, criar o container:
## Executar a imagem
docker run -d -p 8080:80 --name meu-nginx meu-nginx:1.0
docker run: comando que cria e executa um container a partir de uma imagem;-d: essa flag permite que o container rode em segundo plano, liberando o terminal (chamado de modo detached);-p 8080:80: mapeia portas no formato "porta_host:porta_container", permitindo que o que chegue na porta 8080 do host seja direcionado para a porta 80 do container;--name meu-nginx: aqui definimos um nome ao container. Caso você não use, o Docker irá utilizar algum nome aleatório como focused_curie, nervous_hopper ou algo do tipo;meu-nginx:1.0: aqui informamos qual imagem deve ser usada para subir o container.
Com o container em execução, vamos seguir para testar alguns comandos. Bora lá!
Comandos básicos
Já aprendemos a como criar, buildar e executar, vou deixar aqui os comandos básicos para usar no dia-a-dia. Considere-os como um mini kit de sobrevivência, então brinque à vontade com eles:
## Listar os containers em execução
docker container ls
## Listar os containers (incluindo os parados)
docker container ls -a
## Listar imagens
docker image ls
## Inspecionar um container
docker container inspect [ID ou nome do container]
## Ver os logs de um container
docker container logs [ID ou nome do container]
## Ver os logs em tempo real
docker container logs -f [ID ou nome do container]
## Iniciar um container parado
docker container start [ID ou nome do container]
## Parar um container
docker container stop [ID ou nome do container]
## Remover um container
docker container rm [ID ou nome do container]
Observação: para remover um container, ele precisa estar parado. Podemos até usar a flag -f, mas nunca é o ideal.
Acessando um Container
Com o seu kit de sobrevivência em mãos, eis o momento de acessar um container que está rodando. Para entender como funciona, vamos executar um container de forma interativa (com as flags -t para o terminal, e -i para interatividade):
## Criando um container de forma interativa
docker container run --name meu-ubuntu -ti ubuntu
O Docker irá fazer o pull da versão latest do Ubuntu, abrindo o terminal. Olha só que legal, estamos dentro do Ubuntu:
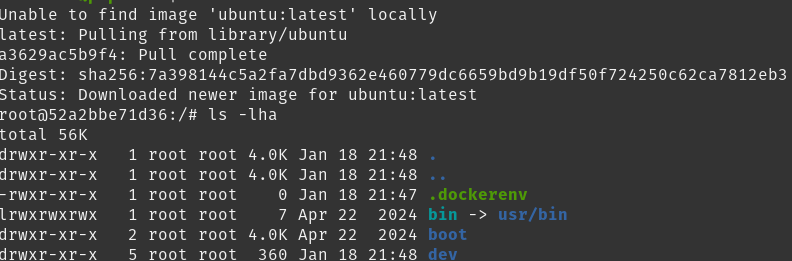
Para sair desse container, jamais use o comando exit ou Ctrl+D, pois isso irá matar o processo principal e encerrar o container.

Então, para sair de forma segura, use Ctrl + P + Q.
Usando o attach
Podemos nos conectar a um container em execução utilizando o comando docker container attach [ID ou nome do container]
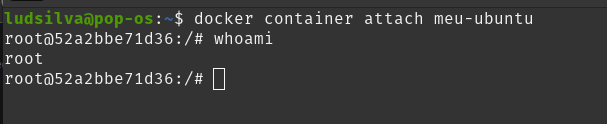
Porém, cabe um adendo importante aqui: o attach conecta diretamente ao processo principal do container. Caso você use um Ctrl + C nesse container, ele vai interromper o processo principal e morrer.
Usando o exec
Com o exec podemos rodar um comando em um container em execução:
Isso possibilita também executar o bash como um novo processo com o docker container exec -it [ID ou nome] bash:
O exec tem uma vantagem bem interessante para este caso: se usarmos o exit ou Ctrl+D, o container continua rodando normalmente. Isto ocorre porque não encerramos o processo principal, sendo esse comando o mais indicado para alguns casos de troubleshooting e manutenção.
Publicando sua imagem no Docker Hub
Já criamos nossa imagem e testamos localmente, agora vamos disponibilizá-la em um repositório (registry) de imagens. Por quê? Bem, porque isso facilita a portabilidade da aplicação, permitindo também armazenar, versionar e compartilhar as imagens.
Existem várias opções de repositórios, tanto públicos quanto privados, mas utilizaremos o Docker Hub por ser o mais popular. Então, para seguirmos é necessário que você crie uma conta aqui.
Após criar sua conta, vamos fazer o login via terminal:
## Docker login
docker login -u nome_de_usuario
OBS: O comando vai pedir a senha, mas você pode usar também um token de acesso.
Em seguida, precisamos renomear a tag da imagem do Nginx que criamos anteriormente, acrescentando o seu nome de usuário, seguindo o padrão usuario/nome-da-imagem:versao):
## Renomear a imagem
docker image tag meu-nginx:1.0 nome_de_usuario/meu-nginx:1.0
Exemplo:

Por fim, vamos fazer o push para o Docker Hub:
## Fazer o push da imagem
docker push nome_de_usuario/meu-nginx:1.0
E voilá! Aqui está a minha querida no repositório e disponível publicamente:

Conclusão
Uau! Foi uma pequena jornada que passamos aqui com o Docker, hein? Mas tem muita coisa para aprender e, como o objetivo deste post era fazer uma introdução ao Docker, muita coisa ficou de fora: volumes, network, multi-stage build, docker compose e por aí vai.
Eu espero que este pequeno guia possa ajudar no seu aprendizado, mas é muito importante que você coloque a mão na massa para fixar melhor.
Por fim, deixo logo abaixo algumas recomendações para seguir seus estudos e se aprofundar no mundo dos containers.
Te vejo na próxima!
Recomendações de leituras e cursos